Unicode characters search tool.
Type a single word to describe your search. Example: 'music', 'bullet', etc.
Description.
The Unicode character set includes just about every character in every known language (there are, of course, some missing),
as well as a number of other characters: mathematical symbols, monetary units, graphic symbols, pictograms, etc.
To help you find the one you are looking for, use the tool below. It allows searches by keyword or by code range. Not all characters are present, in particular, the CJK ideograms, which are very numerous, are not included. Thank you for your understanding.
The 8 characters corresponding to your search are listed below.
Glyphs and character codes.
In the results above, the character itself is displayed in its original colour, with a zoom effect on mouse-over.
- Its decimal code is displayed in orange.
- Its hexadecimal code is displayed in blue.
- Finally, HTML entities, if any, are displayed in green.
1200-137F - Ethiopic.
13A0-13FF - Cherokee.
1980-19DF - New Tai Lue.
1C50-1C7F - Ol Chiki.
2200-22FF - Mathematical Operators.
AB70-ABBF - Cherokee Supplement.
Character names.
1200-137F - Ethiopic.
13A0-13FF - Cherokee.
1980-19DF - New Tai Lue.
New tai lue sign lae
Decimal code : 6622
Hexadecimal code : 19DE
UTF-8 encoding : E1 A7 9E (3 bytes)
HTML Entity(ies) : ᧞
Category : Other Symbol
᧞
Keywords : lae
1C50-1C7F - Ol Chiki.
2200-22FF - Mathematical Operators.
AB70-ABBF - Cherokee Supplement.
Current Searches.
Most common UTF character searches :
Mirror characters.
The result of your search contains mirror characters.
These are characters that work in pairs, and whose shape is symmetrical with respect to the vertical axis.
The most common ones are parentheses, brackets and braces, but many mathematical symbols are also mirroring :
the greater than (>) and lower than (<) symbols, for example.
The shape of the characters is designed for Latin languages, which are written from left to right, but are ill-suited for writing in the opposite direction, as in the case of Arabic languages.
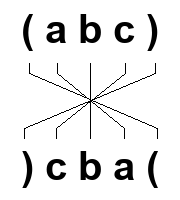
The Unicode standard provides the possibility of replacing a character with its mirror when the writing direction is from right to left, in the case of Arabic languages, for example.
Here are some examples :
| Latin languages From left to right | Arabic languages From right to left | Arabic languages with mirror character processing |
|---|---|---|
| (Unicode) | )edocinU( | (edocinU) |
| max > min | nim > xam | nim < xam |
| « citation » | » noitatic « | « noitatic » |